Background
This article is part of a larger body of research (see other articles below) about how product managers are incorporating machine learning into their products and was conducted by Brian Polidori and myself while MBAs at UC Berkeley with the help of Vince Law as our faculty advisor.
The research is an attempt to understand how product managers are designing, planning, and building ML-enabled Products. To develop this understanding, we interviewed 15 product development experts at various technology companies. Of the 15 companies represented, 14 have a market capitalization greater than $1 billion, 11 are publicly traded, 6 are B2C, and 9 are B2B.
Data strategy principles
Machine learning (ML) enabled Products have a constant cycle of collecting, cleansing, and analyzing data to feed into an ML model. This repeated cycle is what fuels the ML algorithm and allows the ML-enabled Product to deliver useful insights to users.
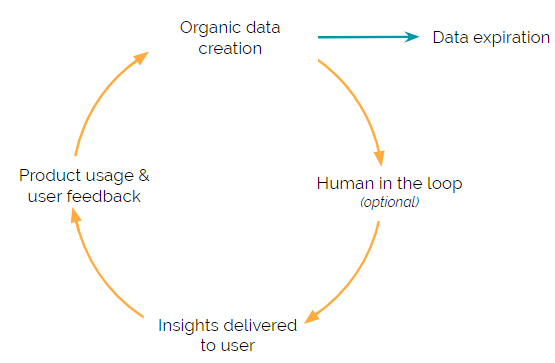
Each step in the cycle presents a unique challenge. Therefore, we’ve explored each of the data strategy steps in-depth with frameworks and examples that highlight some of these unique challenges.
Organic data creation
In business, company growth is typically broken down between organic and inorganic growth. Organic growth is growth that arises from the company’s own business activities while inorganic growth arises from mergers and acquisitions. This same concept can be applied to the data creation process.
Organic data creation is when the data (i.e., the data that is used to inform the ML model) is created as a byproduct of the product itself. Inorganic data creation is when the data is acquired (either purchased or freely accessible) from a third party.
All the largest technology companies operate under an organic data creation strategy.
Facebook knows who to recommend to you as a possible friend connection because you’ve already confirmed your friendship with other similar people. Amazon knows what other products you’re likely to purchase because of all your past purchases and browsing history. And Netflix knows which show to recommend next because of the past shows you’ve watched.
One noted exception is when a company is first starting out. A company may need to inorganically acquire data in order to build an initial ML model and over time use that ML model to create the necessary network effects to start an organic data creation process.
Key points (the four main benefits to organic data creation):
- Cost-effective — ML models need a large volume of data to train on and this data needs to be constantly updated and refreshed (see the Data Expiration section below).
- Representative data — Organic data creation is likely to have data that is representative of your specific users, since it is in fact created by your users.
- Competitive advantage — As a natural byproduct, organic data is proprietary and can serve as a competitive advantage that competitors are unable to replicate.
- Network effects — Organic data creation can increase the power of network effects because, as users increase, so does the data, leading to improved models.
Human feedback
By its very nature, ML is able to ‘learn’ how to optimally perform a task by receiving feedback — lots and lots of feedback. This feedback primarily takes two forms:
- User-generated feedback
- Manual human-in-the-loop review
User-generated feedback
User-generated feedback is organic data creation in action. For many use cases, user-generated feedback is relatively easy to capture. For instance, one of our interviewees gave us the following example — which applies generally to all search use cases.
When a user types a query into this company’s website search bar and hits enter — 20 results are shown. Then the user quickly scans the summary text and (most likely) clicks on one of the 20. The user is the one that is selecting from the list — which is key. Although this is rather obvious, it’s important to elaborate and clearly define why this matters.
The only person in the world that knows which of the 20 results presented is most relevant to the user… is the actual user. Anyone else would just be guessing. So, the user is not only satisfying their own needs but also helping train the ML model with the most accurate data available.
Because of this, in-product user feedback is the most valuable type of feedback your ML model can receive. Also, it doesn’t require you to hire people (unlike human-in-the-loop which is discussed below) and is able to scale as your product scales.
Sometimes, it’s harder to capture user feedback and additional elements have to be added to the use case. The key in adding these additional elements is to build the feedback channels in a way that also improves the user experience and ensures partial adoption.

For example, as LinkedIn started to scale it’s InMail messaging service, it decided to introduce two reply options. When a recruiter reaches out to you, LinkedIn provides two responses, “Yes” or “No Thanks.” This was a simple solution that not only improved the user experience by making it faster for users but also gave LinkedIn highly structured user feedback that they could use to train its ML model. Over time, LinkedIn has introduced more ML-enabled Products like Smart Reply which benefits from the same in-product feedback mechanism.
Key points
- Create structured feedback points in your product where the user is personally incentivized to opt-in to providing feedback (Facebook photo tagging, LinkedIn recruiter response).
- By nature, an individual user’s actions are the most accurate data that an ML model can receive for that specific user.
- Leverage user-generated feedback to enhance your ML models and create a reinforcing network effect between users and ML accuracy.
Human in the loop
Human-in-the-loop feedback is when you pay a person to review a specific use case or data set and provide their educated opinion (e.g., labels, yes/no, etc.). You can also think of this human-in-the-loop process as a mechanical turk, although our interviewees suggested that most companies will likely either hire a third-party firm or create an internal team.
Given how unscalable human-in-the-loop feedback is, we were surprised to find that over half of our interviewees said their company was either currently using or planning on using human-in-the-loop to provide structured feedback to their ML models.
To bring the concept to life, let’s walk through an example.
Quora is a question-and-answer website where questions are asked, answered, and organized by its community of users. To sort through all the noise on the platform, Quora allows users to upvote answers, helping quality responses rise to the top.
Quora noticed that some pieces of content would receive a lot of upvotes, but upon review, the quality would be subpar and had devolved into ‘clickbait’ content. Therefore, to enhance the upvote functionality, Quora decided to also incorporate human-in-the-loop feedback. Quora now sends a small percentage of questions and answers to humans who have been trained according to Quora’s standards (more on that below) to rate the quality of the feed on a numerical scale to feed into their ML models.
Human-in-the-loop feedback is, by its nature, a manual process and is therefore very expensive. Due to the prohibitive costs associated with human-in-the-loop, only large companies appear to be extensively using it for feedback. In fact, some interviewees noted that the cost associated with human-in-the-loop helped the company create a ‘moat’ around the business. For example, Facebook is thought to have a team of over 3,000 working on labeling and content moderation.
As we analyzed the use cases where our interviewees were using human-in-the-loop, we found a couple of overarching reasons.
- The use case doesn’t have an absolute (i.e., universally true) quantitative metric to measure performance. Therefore, humans reviewers are the highest bar for quality where subjective decisions based on nuanced rules are needed.
The Quora example above illustrates this. For specific posts, the engagement metrics that Quora uses to measure ML outcome success may be high, but the human interpreted quality (relative to stated rules) is low.
- There is significant downside risk if the ML model is incorrect and humans have the ability to determine on an individual basis if something is correct or not.
For example, if a social network doesn’t properly perform content moderation, there is a significant public relations risk. Humans who are provided rules can reasonably determine if a piece of content adheres to or breaks those rules.
Taxonomy of rules
One issue that interviewees kept bringing up regarding human-in-the-loop was the difficulty of creating guiding principles, which are used to guide the reviewers doing the manual checking. The guiding principles have to not only be specific enough to limit the amount of ‘grey’ area where a reviewer has to make a subjective decision, but also simple enough so that a reviewer can effectively perform the task.
Many interviewees mentioned that their companies’ guiding principles are hotly debated and constantly in flux.
Key points
- Sometimes, user-generated feedback is not sufficient to meet the goals of the product and needs to be augmented with human-in-the-loop feedback
- Human-in-the-loop evaluators cost a lot of money and the process to efficiently set up this manual review can be even more costly. However, once these procedures are ingrained into the product process, they can lead to a competitive advantage
- Creating a rule taxonomy for human reviewers is difficult. Considerable thought should be devoted to determining the labeling rules to extend the date of data expiration (see data expiration section for more detail).
Data expiration
Of the 15 people we interviewed, 11 mentioned the importance of data timeliness. Some referred to specific regulations or contract requirements that forced them to purge their user specific data after 60–90 days. While others said that the older data was less likely to be informative (see Reddit’s ranking algorithm) or increase predictive value. This data timeliness seemed to apply not only to user-generated data but also to some instances of human-in-the-loop review.
For example, Facebook tries to maintain up-to-date information (e.g., websites, hours, phone numbers, etc.) about the small businesses on its platform. In addition to giving these small businesses ownership of their Facebook page, Facebook also uses a human-in-the-loop reviewer to check a small percentage of the business pages and see if the data is up-to-date.
However, right after a reviewer confirms that a small business’s data is up-to-date, the probability that the data is still up-to-date begins to decrease. As a rule of thumb, we heard that about 6 months after review the data is equally likely to be stale as it is to be up-to-date — however, the time-frame will vary greatly depending on the specific use case.
Companies are in a constant cycle of trying to get new data before their old data becomes stale and irrelevant. This is another reason that companies should have a product built around organic data creation.
Key points
- As soon as data is created, its usefulness in ML models begins to decline and, for some use cases, this data decay happens over the course of days to weeks.
- Due to the short life of data’s usefulness, companies should focus on organic data creation so that new data can constantly be brought into the system.
