Frameworks and examples from 15 product experts at leading technology companies
Background
This article is part of a larger body of research (see other articles below) about how product managers are incorporating machine learning into their products and was conducted by Brian Polidori and myself while MBAs at UC Berkeley with the help of Vince Law as our faculty advisor.
The research is an attempt to understand how product managers are designing, planning, and building machine learning (ML) enabled products. To develop this understanding, we interviewed 15 product development experts at various technology companies. Of the 15 companies represented, 14 have a market capitalization greater than $1 billion, 11 are publicly traded, 6 are B2C, and 9 are B2B.
How to manage a machine learning model
Product managers need to make trade-offs and consideration when building machine learning (ML) enabled products. Different product use cases call for different ML models. Therefore, learning the core principles for how to manage an ML model is a key product manager skill-set.
Balancing precision versus recall
Every ML model will be wrong at some point. Therefore, when building an ML-enabled product, you need to think about the right balance between false positives and false negatives for your specific use case.
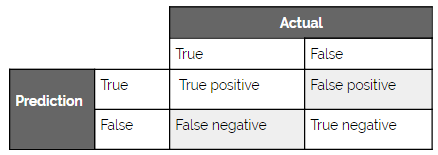
Another way to think about this balance is precision versus recall. Where precision is the percentage of true positives among the retrieved instances and recall is the number of predicted positives over the total number of true positives. The reason the relationship is called a balance is that precision and recall are relatively inversely correlated (when all else is equal).
Although only a few interviewees mentioned this balance using the precision versus recall terminology, a significant portion mentioned the importance of finding balance in their specific use case. Google Photos is a good example to start with.
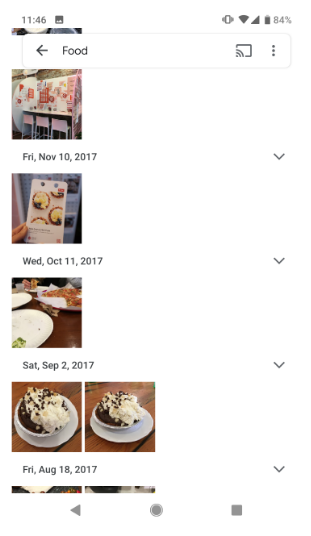
When users type in a search for something in Google Photos, they want to reduce the number of images to make it easier to find exactly what they wanted. Therefore, the goal is noise reduction and, as such, there are limited costs to false positives (since the alternative was looking through all their photos) but high costs to false negative (since what they want might not be surfaced). Hence, Google Photos prioritizes high recall over high precision. Which, as demonstrated in the photo, leads to Google Photos often including images that don’t relate to the search.
On the opposite end of the precision versus recall spectrum, one of our interviewees had an example where their company (a social network) was focused on high precision. The use case was to determine how to rank and recommend content to appear on users’ personal feed. After performing some experiments, the company found that if the recommended content isn’t highly relevant for the user, there is a higher probability of the user churning.
Although this result seems obvious, the nuance was that the highest rates of churn were when the user was on a mobile device. Because of the limited real estate, the recommended content would take up a large portion of the screen and therefore, if the recommended content wasn’t very precise the user would likely churn.
Based on our interviews and research, we’ve created the below general guidelines to serve as a starting point for how to think about what to prioritize.
Key points
When to prioritize recall over precision:
- Anomaly detection
- Compliance
- Fraud detection
When to prioritize precision over recall:
- Limited space (e.g., mobile devices, small sections)
- Recommendations
- Content moderation
Accuracy thresholds
A core part of your machine learning strategy depends on what minimum level of accuracy (the fraction of predictions the model correctly predicts — see the recall and precision section) is needed to achieve product-market fit. A good proxy for product-market fit is value creation, where the more value that is created (for both the company and the users), the better the product-market fit. Thereby, the question becomes, what is the relationship between different levels of accuracy and value creation?
The answer to this question depends on the details of your specific use case. So, let’s go through two examples.
Self-driving cars
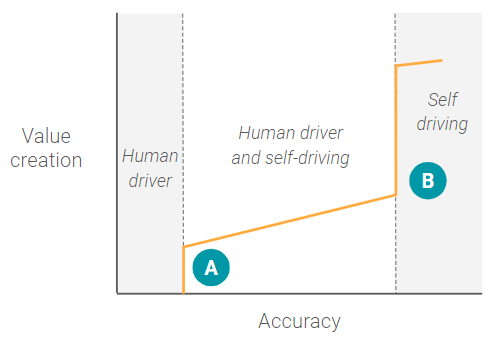
In the beginning, when a self-driving car ML model has a very low level of accuracy, there is zero (or possibly even negative) value creation as a human driver can’t rely on the system at all. At a certain point (A), there is a step-wise function where the ML model has a high enough level of accuracy that a human driver can begin to rely on the system in some highly constrained environments, like freeways where driving is more uniform. Once this accuracy level is reached, there is significant value creation (or product market fit) for that specific use case.
However, after point A, the system reaches a slight plateau where increases in the level of accuracy don’t correspond to commensurate increases in value creation, because the human driver still needs to be involved a portion of the time. For example, the car may be able to park itself a portion of the time, but be unable to handle high-density urban streets, or know exactly where on the side of the street to drop you off. Essentially, the ML model hasn’t yet reached the minimum accuracy threshold for the next use case — full self-driving capability.
Once the ML models reach that minimum accuracy threshold for full self-driving there is a paradigm shift to an entirely new use case that doesn’t involve a human driver at all. At this point, the product team can start thinking about fundamentally changing the product for the new use case, such as adding in entertainment consoles or creating fleets.
Google Photos Search
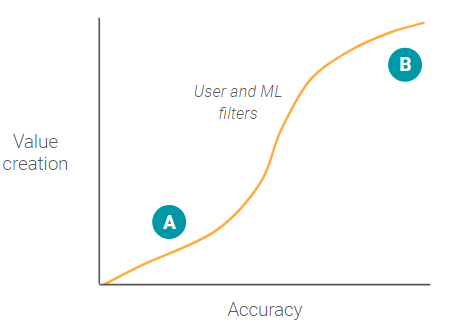
In contrast to the self-driving accuracy value creation graph, the Google photos image search has no large step-wise function.
When a user searches for a specific photo(s), the user types in words to create a filter and reduce the overall number of photos needed to review. Even when accuracy is low, point A, the ML model still creates value by reducing the total number of photos the user needs to look through (assuming the ML model has low false negatives).
As accuracy continues to increase, value creation increases at an increasing rate as more and more irrelevant photos are filtered out. At some point around point B, as accuracy continues increasing, value creation reaches diminishing marginal returns. This occurs because the filter has eliminated the majority of other photos and the user can quickly and easily look at all the photo results without having to scroll.
Every use case will have a different accuracy value creation graph. Therefore, you should carefully think through the characteristics of your specific use case to determine 1) if there are critical accuracy thresholds, and 2) what product changes are necessary above those accuracy thresholds.
Key questions on accuracy thresholds
- What is the minimum accuracy threshold needed for my use case?
- Is machine learning being used to augment a manual process?
- How do the feature requirements of the product change as the percentage of human involvement decreases?
- At what point will you be able to completely remove humans from the process?
- Is there a point where if the accuracy reaches a certain level the entire use case changes?
- Is value creation bounded by zero? Or, in other words, is the maximum value that can be created reducing something to zero, for example reducing fraud to zero?
Exploration vs. Exploitation
One of the major challenges in some machine learning problems is the balance between exploration and exploitation. This problem is often illustrated with a casino scenario called the multi-armed bandit. Imagine a gambler at a row of “one-armed bandit” slot machines. The gambler has the option of testing multiple machines to look for the one that has the highest payout (exploration). Or the gambler can choose a machine and try to build an optimal strategy for winning on that machine (exploitation).
Definitions in terms of maximization (often a metric like click-through rate):
- Exploration — Testing various options somewhat randomly in an attempt to find a global maximum.
- Exploitation — Optimizing the existing problem space for the local maximum.
This trade-off is common for ML-enabled recommendation products. For instance, Nordstroms’ shopping app has limited screen space to promote products to its users. If it shows users new products or brands the user has never looked at, Nordstrom is exploring to see if there is a higher global maximum for that user. This would give Nordstrom more information about the user’s previously unknown preferences (and possibly discover false negatives), but risk negatively impacting user experience with too many false positives.
On the other hand, in a purely exploitative approach, Nordstrom would show users only products and brands that they’ve looked at or previously bought. This approach would help Nordstroms optimize based only on what it already knows about the user (true positives).
This is not a solved machine learning problem; many of the companies we spoke with are constantly optimizing and adjusting their models to find the right balance. The most likely solution will be an ML model that leverages both exploration and exploitation techniques.
Key points
- Exploration is the best way to learn if you have false negatives, but over-exploration could cause many false positives.
- Exploitation is a safe approach, but it is limiting and will likely lead to time spent seeking a less optimal local maximum.
